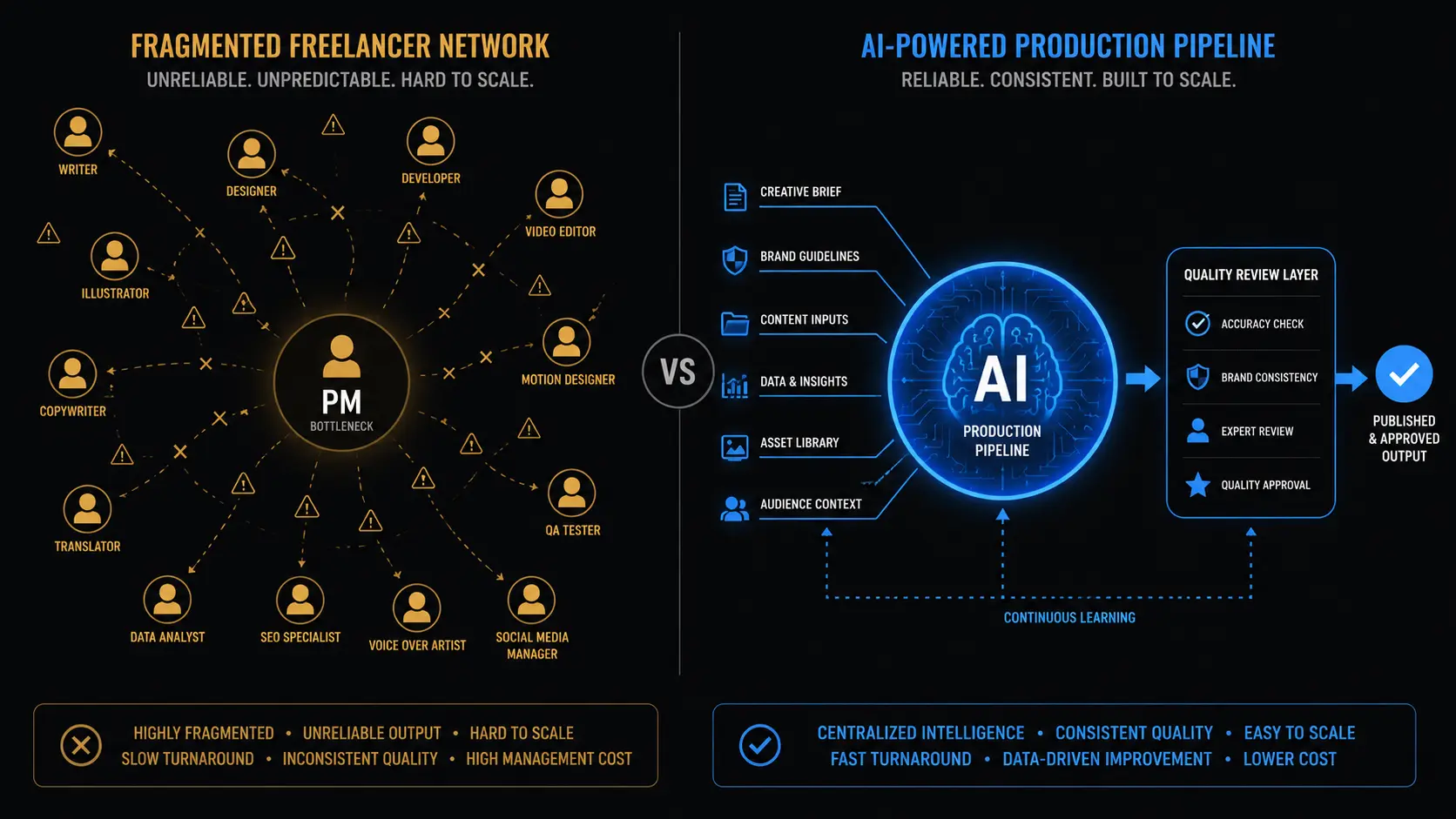
The localization agency that built its Indic-language capability through freelancer networks made the sensible choice for most of the last decade. The alternatives were worse. In-house headcount for 8 to 12 Indic languages was impractical. Global LSPs had nominal language support and poor Indic quality. Freelancer networks, despite their problems, produced acceptable output at a manageable cost for the volume the market required.
The volume the market requires has changed. The ops problems that were tolerable at 50 hours a month become structural at 500 hours a month. And localization agencies managing Indic subtitle and translation work at scale are finding that the freelancer model breaks on three dimensions simultaneously, faster than any of them anticipated.
Replacing a freelancer network with an AI pipeline for Indic-language localization means moving from a model where individual contractors receive, translate, and return project files — with quality controlled by a PM reviewing output and managing revision cycles — to a model where an AI system handles initial transcription, translation, and timing, with human reviewers applying quality assurance to AI-generated output rather than producing the primary output themselves. For Indic language work specifically, the transition requires a pipeline that was trained on Indian language content rather than adapted from a global model, and that incorporates client-specific corrections and brand vocabulary into the model rather than relying on human memory and briefing documents to maintain consistency.
The three operational problems that break the freelancer model at scale
Problem 1: Capacity at volume spikes. Freelancer networks scale reasonably well in steady state. They don't scale well at volume spikes. A streaming platform that delivers 50 hours of subtitle work per month has a manageable freelancer network. The same platform during a major title release — or the same localization agency during a large client's content push — needs to double or triple throughput in two to three weeks. Freelancer networks can't do this cleanly. The available pool for a specific language combination is fixed at any given moment. The reliable freelancers are already allocated. The available slots are filled by less familiar contractors whose quality is unverified against this client's specific standards. The output from the volume spike batch is the batch most likely to require heavy revision — at exactly the moment when the PM has the least capacity to manage it.
The PM time consumed by managing a volume spike in a freelancer network is largely invisible in the project P&L. It doesn't appear as a line item. It appears as PM overtime, delayed project closure, quality failures that require redelivery cycles, and client relationship costs that are harder to quantify but real. For a localization agency whose margin is the difference between what the client pays and what production costs, the hidden PM cost of freelancer network management during volume spikes is often the item that turns a profitable engagement into a marginal one.
Problem 2: Quality inconsistency across the pool. A freelancer network for 8 Indic languages contains dozens of individual contractors with different quality levels, different interpretations of a style guide, different approaches to terminology, and different rates of error on the specific content types the agency handles. The PM's job is to learn which freelancers are reliable for which content types, match assignments accordingly, and manage the correction cycle for the ones who aren't. This is functional at low volume and becomes its own full-time job at scale.
The quality problem is compounded by churn. Freelancers leave the network, reduce availability, increase rates, or shift their specialisation. Every departure requires sourcing, onboarding, and quality-assessing a replacement — at the PM's time cost. A freelancer network that has been stable for two years can lose three or four key contributors in one quarter, degrading quality noticeably before the PM has time to backfill.
The consistency problem is specific to Indic languages in a way that doesn't apply to European language pairs with larger qualified pools. For Hindi, the pool of qualified subtitle freelancers is large enough that consistency is achievable. For Marathi, Bengali, Tamil, and Telugu at production-quality subtitle standards, the pool is smaller and the variance between the best and worst available contractors is larger. For Bhojpuri, Punjabi, and underserved languages, reliable freelancer availability is genuinely constrained and quality variance is significant.
Problem 3: No learning across projects. The fundamental structural problem with freelancer networks for localization work is that they don't improve. A client's glossary is maintained in a document that gets included in every brief. Style guide decisions are communicated via briefing email. Corrections from one batch are noted and shared with the relevant freelancer — but if that freelancer isn't on the next batch, the correction doesn't transfer. A new contractor starts from the agency's standard brief without the benefit of all the corrections that have been made to previous batches for that specific client.
The result is that quality for a given client is determined by which specific freelancers are assigned to each batch, rather than accumulating toward a consistent standard over time. An agency that has been producing Indic subtitle work for a client for two years may be delivering output at exactly the same quality level as the first batch — because nothing in the model has actually improved. An AI pipeline that incorporates corrections is structurally different: client vocabulary, style guide decisions, and correction patterns are maintained in the model and applied to every subsequent batch, regardless of which human reviewers are working on the project.
What the transition to an AI pipeline actually looks like
The transition is not a switch from human to AI. It's a restructuring of where human judgment gets applied in the production workflow. In a freelancer network, the primary production step is human — the translator reads the source and produces the target text, with PM review afterward. In an AI-native pipeline, the primary production step is AI — the model transcribes, translates, and times the subtitle — with human review applied to AI output rather than producing the primary text from scratch.
The human reviewers in an AI-native pipeline are doing a different job than freelance translators in a network. They're not producing text from scratch — they're applying editorial judgment to AI-generated output, catching errors, handling cultural adaptation decisions the AI can't make reliably, and maintaining brand and style consistency. This is a faster and more consistent job than primary translation, which means fewer hours of human time per minute of content — but it requires reviewers who can evaluate quality rather than just produce text, which is a different hiring and management challenge than building a translation freelancer network.
For the localization agency making this transition for Indic language subtitle work, the critical variable is whether the AI pipeline being adopted was genuinely trained on Indian language content or is a global model with Indic language options. A global model used as the production base produces the same error patterns described in previous posts in this cluster — code-switching failures, register mismatches, Devanagari rendering issues — which means the human review step is doing a near-full correction job rather than a light QA pass. The economics of the AI pipeline only work if the AI is accurate enough that human review is genuinely reviewing rather than rewriting. A purpose-built Indic subtitle pipeline produces output accurate enough for human review to be a QA pass rather than a reconstruction job.
The comparison: freelancer network vs AI pipeline across 6 operational criteria
| Criterion | Freelancer network | AI-native pipeline (Indic-specialist) |
|---|---|---|
| Volume spike handling | Constrained by available pool; quality degrades under pressure | Scales to volume without quality degradation; human review is the constraint, not production |
| Quality consistency | Varies by individual contractor; depends on which freelancers are assigned | Consistent AI output quality; variation comes from reviewer judgment, which is easier to manage than translator variance |
| Learning across projects | None — corrections apply to the current batch only; new freelancers start from the standard brief | Corrections incorporated into model; quality improves over time for the specific client's content type |
| PM overhead | High — sourcing, matching, briefing, chasing, reviewing, managing revision cycles | Lower — briefing and QA review; PM is managing quality rather than managing people |
| Freelancer churn risk | Continuous — quality depends on specific individuals who may leave or become unavailable | None — the AI component doesn't churn; reviewer pool is more interchangeable than primary translator pool |
| Underserved language coverage | Limited by available qualified freelancers; some languages have thin reliable pools | Depends on pipeline's training data; a well-trained Indic pipeline covers more languages reliably than most freelancer networks |
Where it works and where it doesn't
Where the transition to AI pipeline makes operational sense
- Agencies running 100+ hours per month of Indic subtitle work where PM overhead for freelancer management is a significant and growing cost
- Agencies with clients who have specific style guide and brand vocabulary requirements that are hard to maintain consistently across a freelancer pool
- Agencies experiencing volume spikes that strain the freelancer network's capacity and produce quality failures at exactly the worst moment
- Agencies building Indic language capability in underserved languages where reliable freelancer availability is structurally limited
Where the freelancer model still has a role
- Highly specialised content types — legal transcription, medical translation — where domain expertise in the subject matter matters more than subtitle production efficiency
- Languages where the AI pipeline doesn't yet have adequate training data, where the human review step would be a full correction job rather than a QA pass
- Very low-volume one-off projects where the setup overhead of an AI pipeline relationship doesn't amortise across the project scope
FAQ
Does switching to an AI pipeline mean reducing translator headcount?
Not necessarily, and framing it that way usually makes the transition harder. The shift is from sourcing, briefing, and managing a network of primary translators to managing a smaller pool of skilled reviewers who evaluate and improve AI output. The roles are different, not simply smaller in number. Agencies that have navigated this transition well have redeployed strong freelancers as quality reviewers rather than eliminated them.
How do I evaluate whether an AI pipeline is ready for my Indic language volume?
Run a pilot on a representative sample of your actual client content — not a demo. Measure the correction rate: how many edits per minute of content does the human reviewer need to make? If the correction rate is close to what a human-only workflow produces, the AI isn't adding value. If it's materially lower — below 5 to 8 corrections per minute on typical content — the human review step is genuinely a QA pass rather than a reconstruction job, and the economics of the pipeline work.
How long does the transition take?
Practically, three to six months to run the parallel operation — AI pipeline producing output alongside the existing freelancer network on the same content — and verify that quality is consistent and margin is improving. The transition doesn't require switching everything at once. Most agencies move language pairs or content types progressively rather than switching the entire operation simultaneously.
Freelancer networks for Indic-language localization work are operationally sound at low volume and structurally fragile at scale. The three failure modes — capacity at volume spikes, quality inconsistency across the pool, and no learning across projects — don't appear suddenly. They accumulate, and they get more expensive as volume grows. The transition to an AI-native pipeline doesn't eliminate human judgment from the workflow. It restructures where that judgment is applied: from primary production, where variance and churn are the main risks, to quality review, where the human reviewer is amplifying an AI baseline rather than building from scratch. For Indic languages specifically, the transition requires a pipeline trained on Indian content — not a global model — because the accuracy gap between the two is what determines whether the human review step is a QA pass or a reconstruction job.
If your agency is managing Indic subtitle volume through a freelancer network and the PM overhead is growing faster than the revenue, the right conversation is about partnership, not tools. ButterCut works with localization agencies as a capacity and quality partner for Indic language subtitle production — not a tool you buy, but a pipeline you plug into. Reach out to discuss how a partnership would work for your specific language mix and volume profile.
Sources
- Doctor eLearning, Top Translation Companies India 2026 — Total Cost of Ownership focus; manual workflows as liability; ₹3-8/word professional human-augmented translation rates
- Locize, Top Translation and Localization Companies 2026 — scalable solutions, AI integration, and global talent networks as differentiators
- VerboLabs, Subtitling Challenges and Best Practices — quality inconsistency and QA overhead in subtitle production workflows
- IntlPull, Subtitle Localization Complete Guide 2026 — AI-assisted first draft with human review as emerging standard workflow